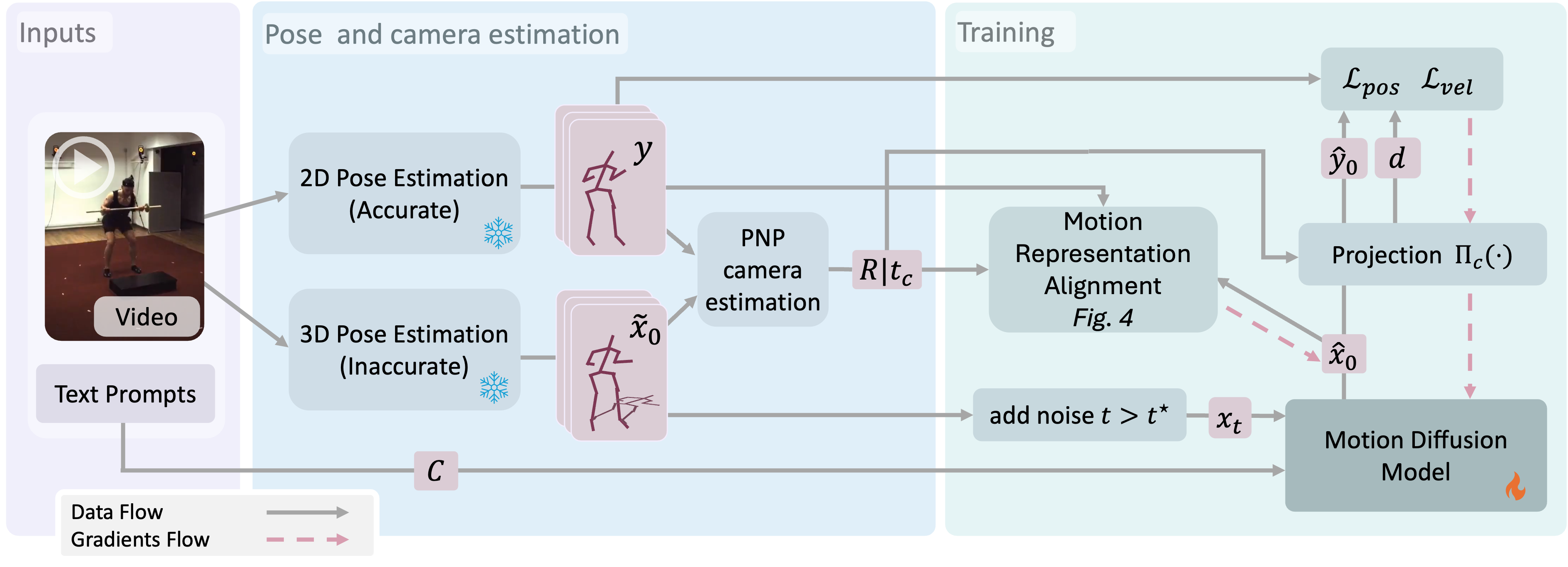
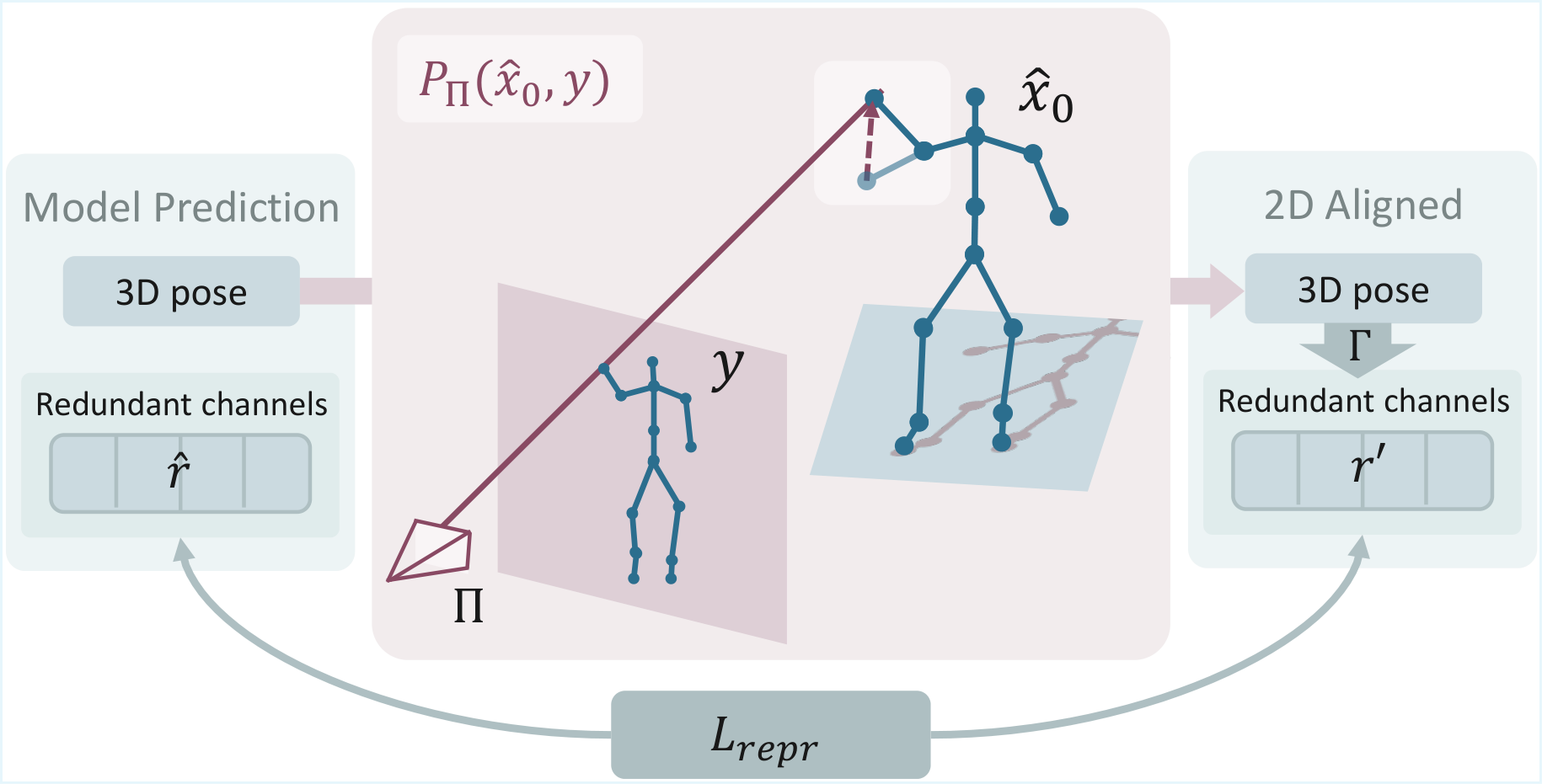
Method
We are given monocular human-motion videos with accurate 2D joint trajectories but no 3D ground truth. A pretrained 2D-to-3D lifter produces approximate 3D pose sequences that serve as a noisy teacher. As in standard diffusion training, we diffuse these lifted 3D estimates and train a denoiser to recover the clean 3D motion — but supervision is applied entirely in 2D by reprojecting the prediction and comparing against the accurate keypoints.
A depth-aware weighting of the reprojection loss is, under mild assumptions, provably equivalent in expectation to direct 3D MSE supervision. We further adapt two standard 3D motion regularizers: a depth-weighted 2D velocity loss for temporal coherence, and a representation alignment loss that supervises the over-parameterized motion channels — joint rotations, velocities, and foot contacts — via ray-projection pseudo-targets derived from the predicted motion and the observed 2D keypoints.